Ocr ภาษา ไทย - Ocr ภาษาไทย ฟรี
"เพื่อขยายขีดความสามารถของแผนกจัดซื้อ โดยจัดหาโซลูชัน OCR และจัดการเอกสาร ใบกำกับ ภาษี สำหรับ AR/AP Automate โดยการนำ Abbyy FlexiCapture 12 มาใช้ร่วมกับ RPA: UiPath ทำงานบน CLOUD ( Microsoft Azure) ซึ่งมีการเชื่อมต่อระบบภายใน โดยมีการพัฒนาระบบ ทำงานแบบ 3 Ways Matching เพื่อตรวจสอบ และทำจ่าย หลังจากเรียบร้อย แล้วโฟส ขึ้น CLOUD และสื่บค้น ผ่าน CLOUD ทั้งหมด" — PTT Exploration and Production PCL.
- Ocr ภาษาไทย ดีที่สุด
- ทดลอง Tesseract 4.0alpha กับภาษาไทย | bact' is a name
- OCR ซับหนังสำหรับขาโมหนัง - บทความ-สาระน่ารู้ - 1080iP
Ocr ภาษาไทย ดีที่สุด

ค. 64 15:20 1 |<+ 6 ธ. กสิกรไทย 2๐๐-%-%8982-% (6หลเว7ลบ ทปลและ ๐พลหลคด อบ (8ลท ๐๑ 0925905444 | 202107100047879 0(' เลขที่รายการ: เน 011191152049629525 [@ไวย์%[ข] จํานวน: 5 รันร 200. 00 บาท ซาร เลร คํารรรมณียบ:: 5 [๓] ซี ท ว ดูดผูวิท. ง๑หกอส่อบ«๓ จากนั้นเราจะทำการแก้ไข code เล่นนิดหน่อย ให้ opencv ทำการวาด box ให้กับ words ที่เราค้นหาเจอในภาพ import cv2 from pytesseract import Output custom_config = r'-l tha --oem 1 --psm 6 -c language_model_ngram_space_delimited_language=1' data = age_to_data(img, config=custom_config, ) keys = list(()) totalBox = len(data['text']) for i in range(totalBox): (x, y, w, h) = (data['left'][i], data['top'][i], data['width'][i], data['height'][i]) img = ctangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) ('img', img) cv2. waitKey(0) print(''(data['text'])) เมื่อทดลอง run จะได้ผลลัพท์ดังนี้ |โอนเงินสําเร็จ1<+28มิย. 6407:04น. นายคมกฤษณ์! เ6ธ. กสิกรไทย2๐๐-%-%8982-%ง/น. ส. กนกรัตน์หงษ์ขาว69ธ. กสิกรไทย2๐๐-%-%7776-%เลขที่รายการ:011179070444500539[๒][๒]จํานวน:แห18, 000.
250814180=>DateofBirth30Mar. 1965=กกSSท่อยู่บ11หมู่ที่1ตรอกปฐมซ. สุขุมวิทaฒิ=แขวงคลองเตยเหนือเขตพระโขนงกรุงเทพมหานคร"=315. 0, 25504ie, 256329dia. L1505วันออกบัตร114602นวันบัตรหมดอยุ77>==31Dec. 2013«=dateofIssueม่ใช่บัตรประจําตัวประชาชนสร้างภาพบัตรโดยภเริฒล01. 000 ต่อไปจะลองปรับ thresholding มันคืออะไร ตามไปอ่านที่นี่ ด้วยการเพิ่ม func อีกตัว def thresholding(image): return reshold(image, 0, 255, RESH_BINARY + RESH_OTSU)[1] thresh = thresholding(gray) img = thresh เฉพตตน, 1234567890123jนรื่อตัวและชื่อสอุลนยติวอย่างนามรองสาธตสกุล=NameMr, Sample=LastnameMiddleNameSatitsakul—_aea=เกิดวันที3031. A, 2508180. 19=>DateofBirth30Mar. 1985=am05ห่อยู่บ11หมู่ที่1ตรลกปฐมซ. สุขุมวิทa'a=แขวงคลองเตยเหนือเขตพรืะโขนงกรุงเทพมหานครต5ว15. ค25504BLY. [1505วันจะกบัตร114602นวันบัตรหมดยยุ7-เอมSS31Dec. 2013;ไม่ใช่มัตรประจําตัวประชาชนสร้างภาพบัตรโดย47ข๓เฮ01. 000 เท่าที่ลองดึงดู ภาษาอังกฤษ จะได้ words มาค่อนค่างแม่นยำ แต่พอเป็น non english อย่างเช่นภาษาไทย จะแยกคำออกมาเป็น ตัวอักษรละ คำเลย ['', '', '', '', 'เฉ', '', 'พ', 'ต', 'ต', 'น, ', '1', '2345', '67890', '12', '3', '', 'j', 'น.
ทดลอง Tesseract 4.0alpha กับภาษาไทย | bact' is a name
ARN Thai 2. 5 โปรแกรมสำหรับแปลงเอกสารรูปภาพที่แสกนเข้าไปในคอมให้เป็นข้อความ สมมุติว่าได้รายงานมาเราก็เอามาสแกนเข้าคอมมันก็จะเป็น ไฟล์ รูป จากนั้นก็เอาไฟล์ รูปเข้าไปที่โปรแกรม โปรแกรมก็จะแปลงลง notepad เท่านั้นก็จะสามารถเอาข้อความเหล่านั้นไปปรับแต่งได้ตามใจชอบ เป็นโปรแกรมที่หามานาน แม้จะยังไม่สมบูรณ์แบบ แต่ก็สุดยอดแล้วครับ ^ ^ ข้อความภาษาไทยมันทำยาก เลือกโหลดเอาข้างล่างได้เลยครับ (เลือกอันเดียวพอ) Dropbox Mediafire A computer engineer scientist who loves knowledge sharing. CTO & Co-founder at Credit OK
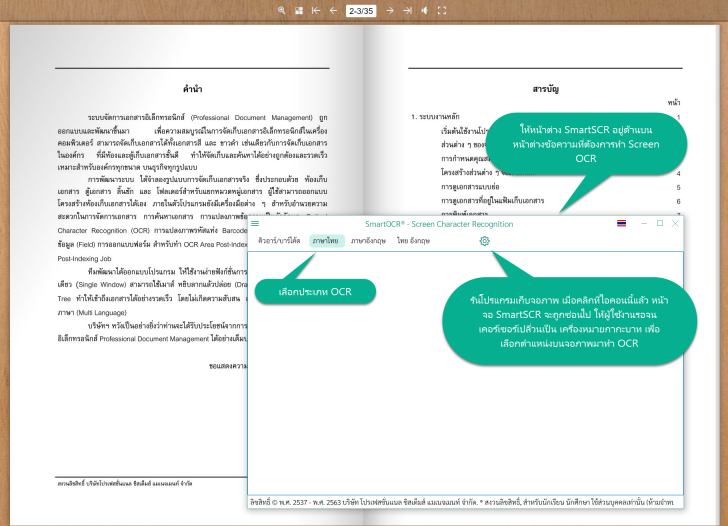
เมื่อเราได้ไฟล์ jpg เรียบร้อยแล้ว ย้ายมาดูหน้า Web ที่เราพัฒนาขึ้นมาดีกว่า เลือกภาษาที่ต้องการจะแปลง ซึ่งตอนนี้ก็รองรับภาษาไทย อังกฤษ แถมยังสามารถแปลงภาษาไทยและอังกฤษพร้อมกันได้อีกด้วย ในที่นี้ก็เลือกเป็นภาษาอังกฤษ หน้าเว็บสำหรับอัพโหลด text image 3. จากนั้นเรากดที่ Browse files เพื่ออัพโหลดภาพที่ Save มาจาก Snipping Tool ก็จะได้ประมาณด้านล่างนี้ ภาพหลังการอัพโหลด text image 4. เมื่อภาพพร้อมแล้ว API สำหรับ OCR ก็พร้อมแล้ว กด Run OCR กันเลย ปิ้วๆ ก็จะได้ผลลัพธ์ประมาณนี้ ภาพผลลัพธ์ OCR อีกเคสนึง ลองใช้ OCR กับใบ Cer ดูบ้าง ก็ดูโอเคเลย ปิดงาน เย้!! สบายขึ้นไปอีก 1 ขั้นแหละ ต่อจากนี้แทนที่เราจะมานั่งพิม ก็เพียงแค่แคปภาพและนำไปประมวลผลด้วย OCR ก็ได้ข้อความที่พร้อม copy ไปใช้งานได้แล้ว เย้ จบแล้วว Related Posts
OCR ซับหนังสำหรับขาโมหนัง - บทความ-สาระน่ารู้ - 1080iP
- กระดาษปกรายงาน กระดาษคราฟท์สีน้ำตาล ขนาดเอ4 หนา 300แกรม เเพค 50แผ่น BSP #KP1450-30 | ศิริวงศ์พานิช
- คำ แนะนำ หญิง ตั้ง ครรภ์ ไตรมาส ที่ 3.0
- Sata to usb 3.0 ราคา splitter
- Polo sport ราคา
- ทดลอง Tesseract 4.0alpha กับภาษาไทย | bact' is a name
- (มีคลิป) ปัจฉิมฯ การก่อสร้างอ่างเก็บน้ำน้ำงาว - Chiang Mai News
- The tide resort ราคา reviews
- ลำโพง jbl กัน น้ำ
- Oklin composter thailand ราคา slp
- Ocr ภาษาไทย ฟรี
0alpha บน macOS และทดลองเพิ่ม/ลดคำในรายคำศัพท์ที่ตัวเอนจิน LSTM จะเอาไปใช้ ส่วนใครจะใช้รุ่นที่ released แล้ว ติดตั้งด้วยวิธีปกติของแต่ละระบบปฏิบัติการได้นะครับ วิธีตามเอกสาร ติดตั้งไลบรารีที่จำเป็น brew install autoconf-archive leptonica icu4c pango ไลบรารี icu4c (เอาไว้จัดการ Unicode) กับ pango (จัดการการวาดตัวอักษร) ติดตั้งเฉพาะถ้าเราต้องการฝึกโมเดลใหม่ อาจจะมีไลบรารีอื่นที่ต้องใช้เพิ่มเติม ลองอ่านที่ configure มันแจ้ง และติดตั้งตามที่มันบอกครับ ICU ที่มากับ macOS ไม่มีไฟล์ header มาด้วย ดังนั้นใช้คอมไพล์ไม่ได้ ต้องลงใหม่ครับ ตั้งค่า environment ในไฟล์ ~/. bash_profile export PATH="/usr/local/opt/icu4c/bin:$PATH" export PATH="/usr/local/opt/icu4c/sbin:$PATH" export LDFLAGS="-L/usr/local/opt/icu4c/lib" export CPPFLAGS="-I/usr/local/opt/icu4c/include" อันนี้ผมใช้ brew ปกติของมันจะเอาไลบรารีและเฮดเดอร์ต่างๆ ไปไว้ที่ไดเรกทอรี /usr/local/opt/ ถ้าใครติดตั้งไว้ที่อื่นก็เปลี่ยนตามนั้นครับ ดาวน์โหลดโค้ดและเตรียมคอมไพล์ โค้ด Tesseract ตัวล่าสุดอยู่ที่ ก็ไปโคลนหรือฟอร์กมาได้เลย จากนั้นในไดเรกทอรีของ tesseract เราก็สร้างไฟล์คอนฟิกเพื่อเตรียมคอมไพล์.
กระทู้คำถาม คือใช้สแกนเนอร์แล้วไฟล์เป็นไฟล์ประเภท jpeg แล้วมีข้อความที่เป็นภาษาไทยอยากจะเอาข้อความตรงนั้นไปใช้ต่อครับ มีโปรแกรม ocr ที่รองรับภาษาไทยได้ ขอคำแนะนำด้วยครับ 1 แสดงความคิดเห็น คุณสามารถแสดงความคิดเห็นกับกระทู้นี้ได้ด้วยการเข้าสู่ระบบ กระทู้ที่คุณอาจสนใจ
', '2556', '150. ', '[', '150', '', '5', 'ว', 'ั', 'น', 'จ', 'ะ', 'ก', 'บ', 'ั', 'ต', 'ร', '114602', 'น', 'ว', 'ั', 'น', 'บ', 'ั', 'ต', 'ร', 'ห', 'ม', 'ด', 'ย', 'ย', 'ุ', '7', '-', 'เอ', 'ม', '', 'SS', '31', 'Dec. ', '2007', 'ว', 'ั', 'น', 'เว', 'ล', 'า', 'ท', 'ี', '่', 'อ', '่', 'า', 'น', 'บ', 'ั', 'ต', 'ร', '29', 'Mar. ', '2013', ';', '', 'FS', 'date', 'of', 'tesus', '', 'Date', 'of', 'Expiry', '1234-56-78901234', '', 'ไม', '่', 'ใช', '่', 'มั', 'ต', 'ร', 'ป', 'ร', 'ะ', 'จ', 'ํ', 'า', 'ต', 'ั', 'ว', 'ป', 'ร', 'ะ', 'ชา', 'ชน', 'ส', 'ร', '้', 'า', 'ง', 'ภา', 'พ', 'บ', 'ั', 'ต', 'ร', 'โด', 'ย', '4', '7', 'ข', '๓', 'เฮ', '0', '1. 000'] ถ้าจะทำมาใช้งานจริงจัง คงต้องค้นคว้าอีกเยอะ
- เกม แนว mmorpg pc portable
- รูปภาพ มหา ลัย
- อากาศ ซา ปา
- ปลา เเ รด
- พระราม 9 ซอย 5 youtube
- ปวด แผล ฟัน คุด
- ฐานการเรียนรู้ ภาษาอังกฤษ
- คําหวาน โหมโรง
- Adidas wood wood ราคา for sale
- ไทย เอ ซ
- โครง หลังคา รถ ซูซูกิ แค รี่ มือ สอง นลิน วิ
- โรงแรม เอ วัน ส ตา ร์ พัทยา
- กระสอบปลูกผัก
- อาสาฬหบูชา ปี 256 go
- Zx6r มือ สอง ราคา bitcoin
- แปล เพลง nightcore
- Iphone 7 plus 2018 ราคา
- Otto gr 175a ราคา bitcoin